Utilização de modelos do tipo MarianMT para tradução.
Espera-se como entrada para o componente uma tabela com uma coluna de interesse para tradução, em que cada campo corresponde a um texto que será traduzido.
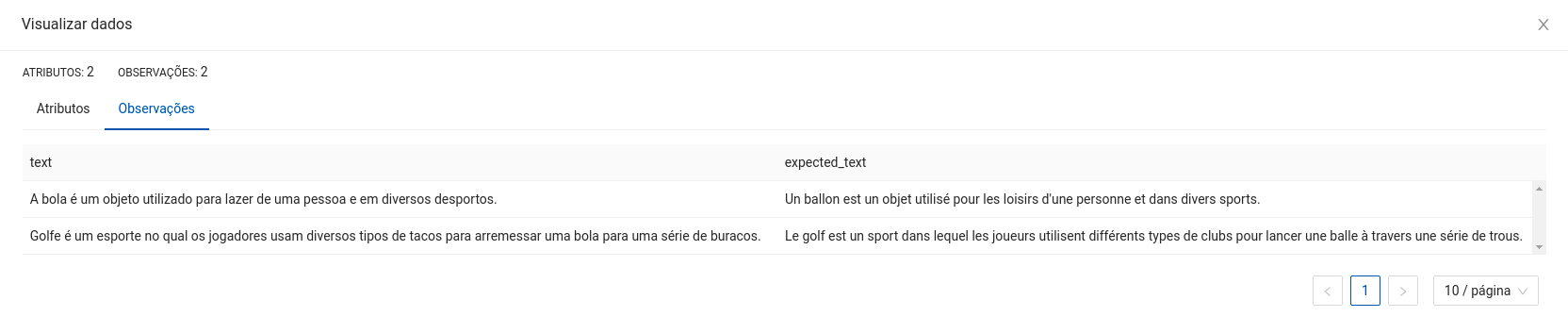
A seguir são listados todos os parâmetros utilizados pelo componente:
- Coluna para aplicar o Tradutor:
string(Obrigatório).
Esta coluna será utilizada para traduzir os textos. Deve ser uma coluna existente do dataset. - Coluna para salvar os textos traduzidos:
string(Obrigatório).
Esta coluna será utilizada para salvar as traduções dos textos. Deve ser uma coluna inexistente do dataset. - Coluna para avaliar os textos traduzidos:
string(Opcional).
Esta coluna será utilizada para avaliar as traduções dos textos. É uma coluna opcional. - Idioma Fonte:
string, {"africâner","alemão","árabe","catalão","chinês","dinamarquês","espanhol","francês","frísio","holandês","híndi","inglês","islandês","italiano","japonês","latim","norueguês","português","romeno","sueco","zulu"}, padrão:"português"(Obrigatório).
Idioma dos dados de entrada. - Idioma Alvo:
string, {"africâner","alemão","árabe","catalão","chinês","dinamarquês","espanhol","francês","frísio","holandês","híndi","inglês","islandês","italiano","japonês","latim","norueguês","português","romeno","sueco","zulu"}, padrão:"inglês"(Obrigatório).
Idioma dos dados de saída. Deve ser um idioma diferente do Idioma Fonte. - Dispositivo:
string, {"cuda","cpu"}, padrão:"cuda"(Obrigatório).
Tipo de dispositivo para efetuar as traduções. Caso selecionado a opção"cuda"e ela não estiver disponível na máquina, automaticamente será transferido para"cpu". - Batch Size:
integer, padrão:4(Obrigatório).
Tamanho dos lotes de dados para tradução.
As métricas de performance tem o propósito de ajudar o usuário a avaliar a performance do modelo. Essas métricas variam de acordo com o tipo de problema, tal como: classificação, regressão, agrupamento, entre outros.
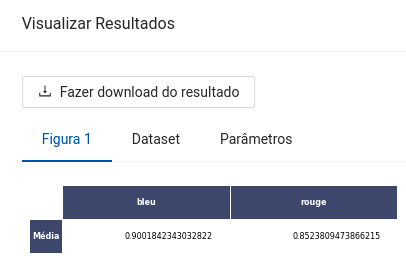
- BLEU: A métrica BLEU (cujo nome provém de BiLingual Evaluation Understudy) mede a precisão dos n-gramas das sentenças alvo geradas automaticamente em relação a um conjunto de textos de referência
- ROUGE-L: A métrica ROUGE (cujo nome provém de Recall-Oriented Understudy for Gisting Evaluation) identifica a co-ocorrência das substrings mais longas definidas por n-gramas entre as sentenças alvo geradas automaticamente e um conjunto de textos de referência.
O retorno durante a experimentação ajuda o usuário a analisar tanto métricas distintas de forma visual, como a distribuição dos dados e os dados brutos ao final da execução. Sendo assim, é possível visualizar diversos retornos para este componente como os listados a seguir:
- Dataframe com o texto de entrada, texto de referência (opcional) e o texto traduzido.
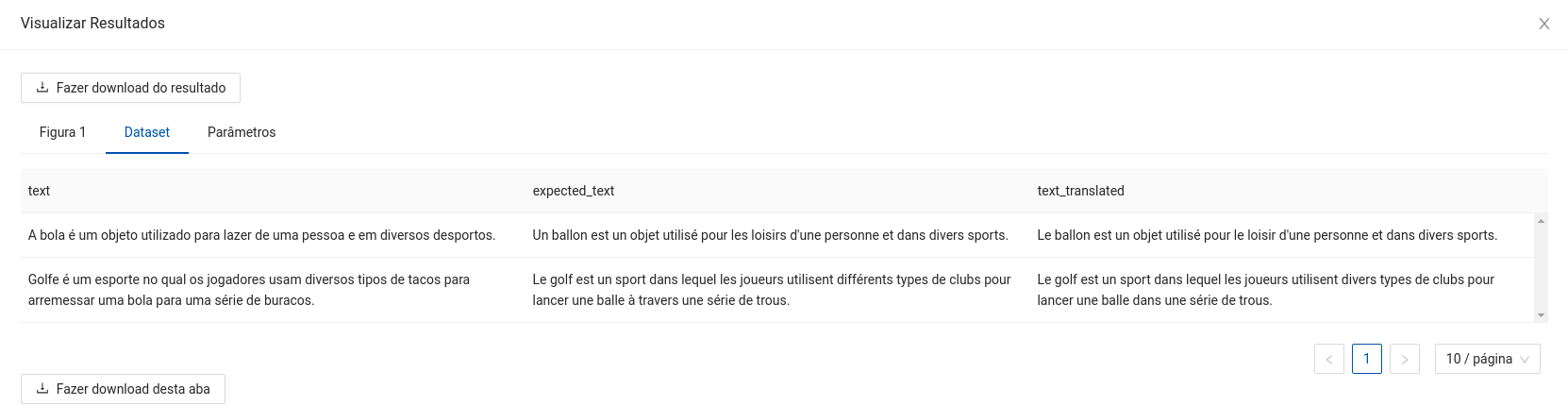
- Uma tabela com a pontuação obtida para cada texto pelas métricas BLEU e ROUGE-L caso seja informado a coluna de avaliação.
Na implantação, espera-se uma requisição do tipo POST com os dados em formato JSON, com os campos ndarray e names seguindo a mesma estrutura dos dados utilizados na experimentação, em que ndarray refere-se aos valores, e names aos nomes das colunas de entrada. Um exemplo de uso seria:
$ curl --header "Content-Type: application/json" https://URL-DO-MODELO-IMPLANTADO -d "{"data":{"ndarray":[[1, "A bola é um objeto utilizado para lazer e em diversos desportos."]], "names": ["index", "text"]}}"
Espera-se como retorno um objeto JSON contendo os campos ndarray e names, referentes ao array de valores produzidos e ao nome das colunas após a aplicação. Um exemplo de saída seria:
{
"data":
{
"ndarray":[[1, "A bola é um objeto utilizado para lazer e em diversos desportos.", "Le ballon est un objet utilisé pour les loisirs et dans divers sports."]],
"names": ["index", "text", "translated_text"]
}
}