O objetivo deste componente é elencar a probabilidade de um conjunto de contextos conter a resposta a uma dada pergunta. Este componente utiliza diferentes modelos de similaridade entre textos para a sua inferência.
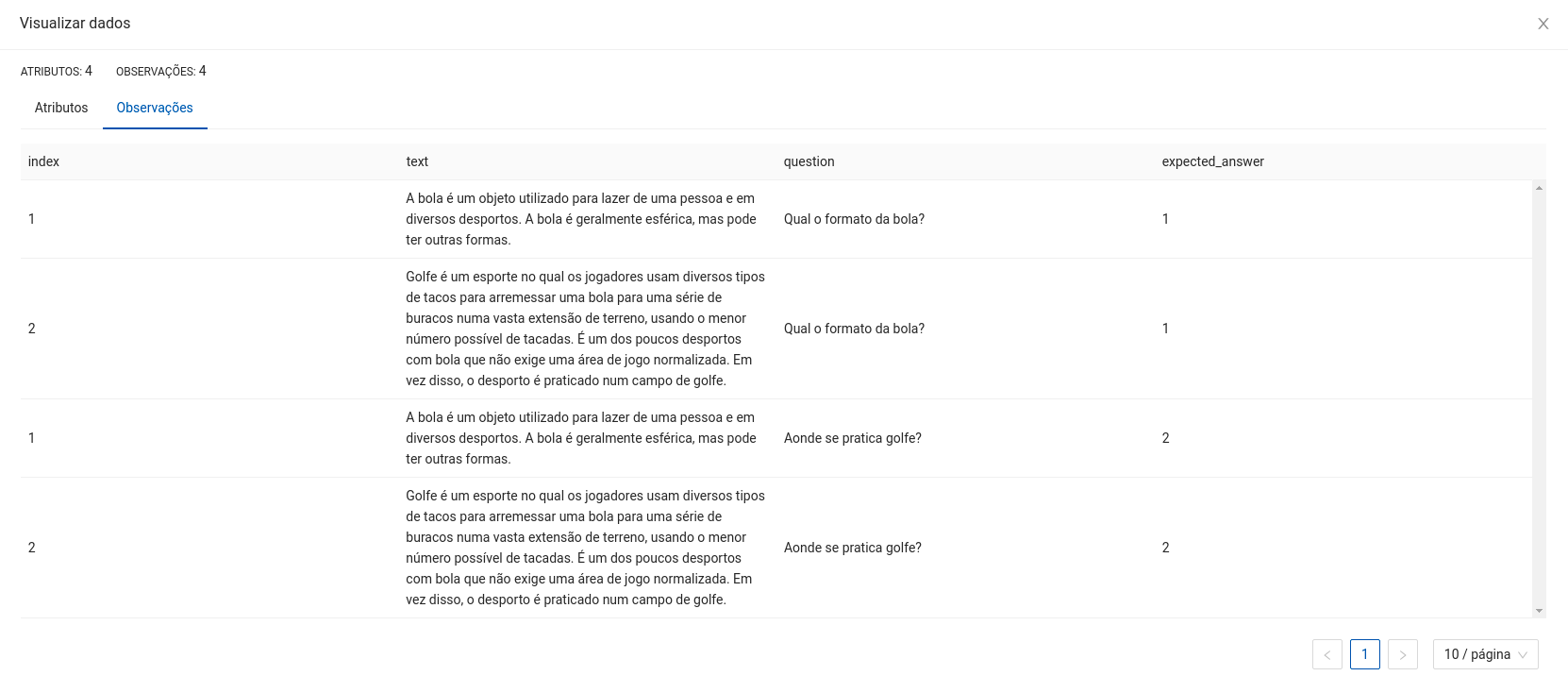
- Neste exemplo são feitas duas perguntas distintas para dois contextos distintos.
- A métrica computada é o MRR.
Espera-se como entrada para o componente uma tabela com uma coluna de contextos para a aplicação do Retriever e uma coluna com as perguntas para serem aplicadas aos contextos.
A seguir são listados todos os parâmetros utilizados pelo componente:
- Coluna dos contextos:
string(Obrigatório).
Esta coluna será utilizada para ler os contextos e aplicar o Retriever. - Coluna das perguntas:
string(Obrigatório).
Esta coluna será utilizada para identificar as perguntas a serem aplicadas aos contextos. - Top N contextos:
integer(Obrigatório).
O número máximo de contextos para elencar por pergunta. Os contextos elencados correspondem aos que obtiveram melhor pontuação do Retriever. - Coluna da pontuação das respostas:
string(Obrigatório).
Esta coluna será utilizada para salvar a pontuação dos N contextos selecionados de cada pergunta. - Coluna de avaliação:
string(Opcional).
Esta coluna será utilizada para avaliar as respostas produzidas por cada pergunta, deve conter a indicação do contexto esperado para o Retriever. É uma coluna opcional, mas caso preenchido deve ser também preenchida uma coluna de identificação dos contextos. - Coluna de identificação dos Contextos:
string(Opcional).
Esta coluna será utilizada para identificar os contextos caso seja informado uma coluna de avaliação. - Dispositivo:
string, {"cuda","cpu"}, padrão:"cuda"(Obrigatório).
Tipo de dispositivo para efetuar as inferências. Caso selecionado a opção"cuda"e ela não estiver disponível na máquina, automaticamente será transferido para"cpu". - Modelo do Retriever:
string, {"paraphrase_multilingual","bm25","tf_idf","word2vec"}, padrão:"paraphrase_multilingual"(Obrigatório).
Modelo para a inferência do Retriever.
As métricas de performance tem o propósito de ajudar o usuário a avaliar a performance do modelo. Essas métricas variam de acordo com o tipo de problema, tal como: classificação, regressão, agrupamento, entre outros.
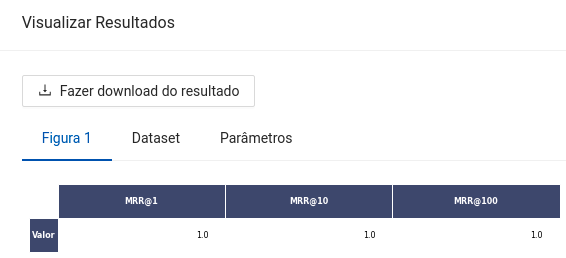
- MRR: A métrica MRR (cujo nome provém de Mean Reciprocal Rank) mede a precisão da ordenação dos contextos mais prováveis de conterem a resposta de uma determinada pergunta. Comumente a notação é dada por MRR@
rank, em queranké o número N de contextos que serão elencados.
O retorno durante a experimentação ajuda o usuário a analisar tanto métricas distintas de forma visual, como a distribuição dos dados e os dados brutos ao final da execução. Sendo assim, é possível visualizar diversos retornos para este componente como os listados a seguir:
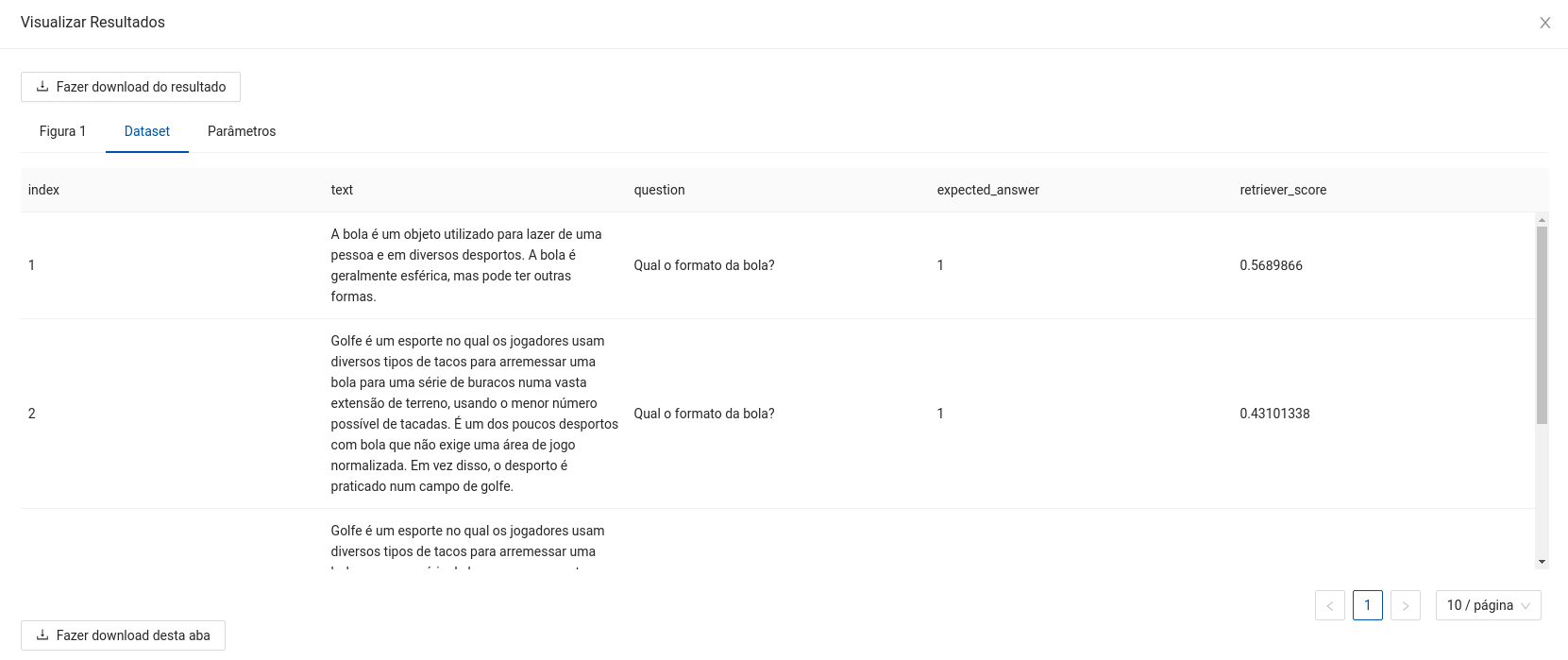
- Dataframe com os dados de entrada e a coluna ordenada pela pontuação calculada por cada par contexto e pergunta.
- Uma tabela com a pontuação obtida para cada texto pela métrica MRR caso seja informado a coluna de avaliação.
Na implantação, espera-se uma requisição do tipo POST com os dados em formato JSON, com os campos ndarray e names seguindo a mesma estrutura dos dados utilizados na experimentação, em que ndarray refere-se aos valores, e names aos nomes das colunas de entrada. Um exemplo de uso seria:
$ curl --header "Content-Type: application/json" https://URL-DO-MODELO-IMPLANTADO -d "{"data":{"ndarray":[[1, "A bola é um objeto esférico utilizado para lazer e em diversos desportos.", "Qual é o formato da bola?"], [1, "A bola é um objeto esférico utilizado para lazer e em diversos desportos.", "Quando foi assinado o Tratado de Versalhes?"]], "names": ["index", "text", "question"]}}"
Espera-se como retorno um objeto JSON contendo os campos ndarray e names, referentes ao array de valores produzidos e ao nome das colunas após a aplicação. Um exemplo de saída seria:
{
"data":
{
"ndarray":[
[1, "A bola é um objeto esférico utilizado para lazer e em diversos desportos.", "Qual é o formato da bola?", 0.754],
[1, "A bola é um objeto esférico utilizado para lazer e em diversos desportos.", "Quando foi assinado o Tratado de Versalhes?", 0.246]
],
"names": ["index", "text", "question", "retriever_score"]
}
}