Este é um componente que treina um modelo K-Means usando Scikit-learn.
Scikit-learn é uma biblioteca open source de machine learning que suporta apredizado supervisionado e não supervisionado.Também provê várias ferramentas para ajustes de modelos, pré-processamento de dados, seleção e avaliação de modelos, além de outras funcionalidades. A tarefa de clusterização é útil nos cenários nos quais se espera descobrir se o dataset pode ser separado em grupos com características semelhantes. Por meio do gráfico de "Distribuição dos Dados de Teste", é possível observar os grupos (ou clusters) obtidos.
Espera-se como entrada para o componente uma tabela com colunas que representam valores numéricos, categóricos ou de data. Os valores de data devem ser removidos ou selecionados para codificação ordinal para que o modelo consiga processá-los. A tabela deve ser de um dos seguintes tipos: Comma-separated values (.csv) ou Excel (.xls, .xlsx).
A seguir são listados todos os parâmetros utilizados pelo componente:
- Quantidade de clusters:
integer, padrão:3.
O KMeans utiliza uma quantidade K de clusters para separar os dados. - Quantidade de sementes:
integer, padrão:10.
Número de vezes que o algoritmo será executado com diferentes sementes de centróide. - Número de iterações:
integer, padrão:300.
Número máximo de iterações do algoritmo em uma única execução. - Gráficos a serem ignorados:
string, {"Dados de Teste","Tabelas de Dados"}.
Considerando a quantidade de gráficos que são retornados ao executar a experimentação, o usuário pode selecionar quais ele não deseja visualizar. Métricas de performance As métricas de performance tem o propósito de ajudar o usuário a avaliar a performance do modelo. Essas métricas variam de acordo com o tipo de problema, tal como: classificação, regressão, agrupamento, entre outros.
- Pontuação de Silhouette: Avalia a qualidade dos clusters criados usando algoritmos de clustering em termos de quão bem as amostras são agrupadas com outras amostras semelhantes entre si.
- Pontuação de Calinski e Harabasz: A pontuação é definida como a razão entre a dispersão dentro do cluster e a dispersão entre os cluster.
- Pontuação Davies e Bouldin: A pontuação é definida como a medida de similaridade média de cada cluster com seu cluster mais semelhante, onde a similaridade é a razão entre as distâncias dentro do cluster e entre as distâncias entre os cluster. Assim, os clusters mais distantes e menos dispersos resultarão em uma pontuação melhor. Retorno esperado na experimentação
- Dados de teste
Apresenta a distribuição dos dados de teste, sendo que as cores indicam os grupos obtidos. Nos eixos, temos as duas componentes mais importantes obtidas por meio da análise de componentes principais (PCA, Principal Component Analysis). Neste caso, PCA foi aplicado para possibilitar a visualização dos agrupamentos em duas dimensões.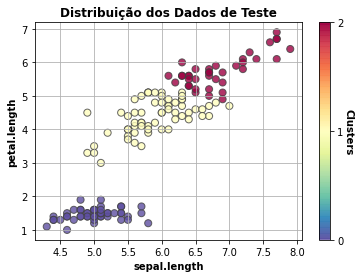
- Tabela dos dados
Apresenta visualização dos dados após o treinamento do modelo com a variável resposta e dados sobre o modelo.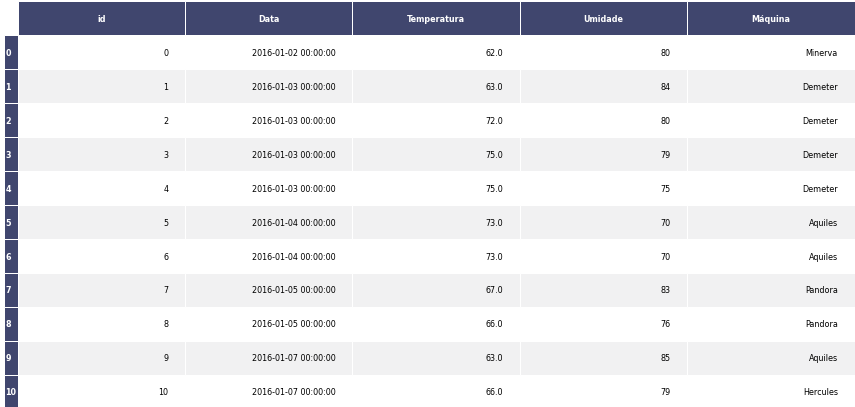 Retorno esperado na implantação Tabela com os valores preditos dos clusters.
Retorno esperado na implantação Tabela com os valores preditos dos clusters.