Separação de textos em partes menores, mantendo uma porção de sobreposição.
- Neste exemplo a aplicação do Chunker é feita separando as expressões considerando as palavras, mas também pode ser realizada considerando períodos. Os períodos (usualmente limitados ao ponto final
.) são definidos pela aplicação do NLTK, que é uma biblioteca de linguagem natural. - No exemplo são considerados os parâmetros
Chunk SizeeChunk Overlapsendo 10 e 4, respectivamente.
Espera-se como entrada para o componente uma tabela com uma coluna de interesse para a aplicação do Chunker, em que cada campo corresponde a um texto que será quebrado em partes menores.
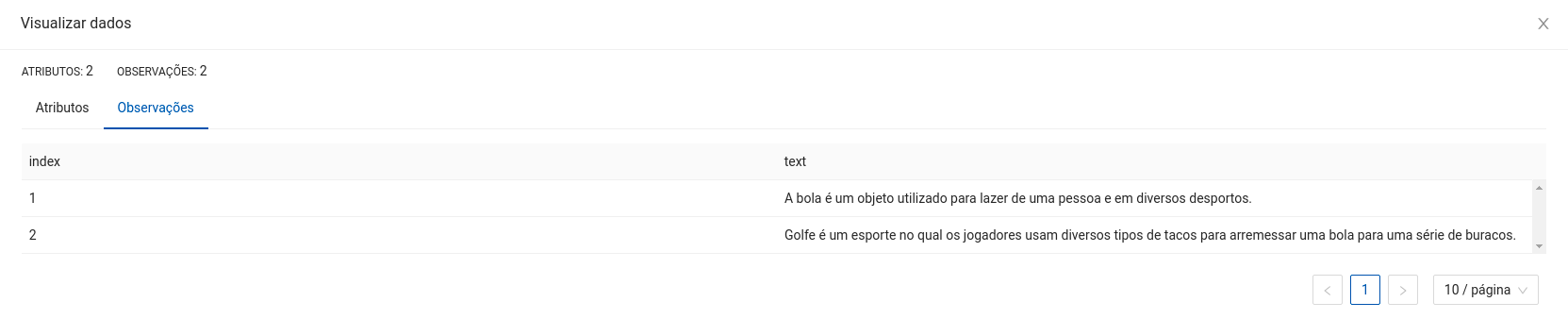
A seguir são listados todos os parâmetros utilizados pelo componente:
- Coluna para aplicar o Chunker:
string(Obrigatório).
Esta coluna será utilizada para criar os chunks de textos. Deve ser uma coluna existente do dataset. - Coluna para salvar os chunks gerados:
string(Obrigatório).
Esta coluna será utilizada para salvar os chunks de textos. Deve ser uma coluna inexistente do dataset. - Chunkenizer:
string, {"word","sentence"}, padrão:"word"(Obrigatório).
Tipo de chunkenizer para aplicar nos dados;"word"separa textos em palavras,"sentence"separa em sentenças. - Chunk Size:
integer, padrão:96(Obrigatório).
Tamanho das janelas criadas pelo Chunker. - Chunk Size:
integer, padrão:64(Obrigatório).
Tamanho da sobreposição das janelas criadas pelo Chunker. - Replicar Dados:
string, {"sim","não"}, padrão:"sim"(Obrigatório).
Optando por replicar os dados, para cada chunk criado a partir de um campo de texto de uma linha da tabela, todos os dados desta linha serão replicados de acordo com a quantidade de chunks produzidos.
O retorno durante a experimentação ajuda o usuário a analisar tanto métricas distintas de forma visual, como a distribuição dos dados e os dados brutos ao final da execução. Sendo assim, é possível visualizar diversos retornos para este componente como os listados a seguir:
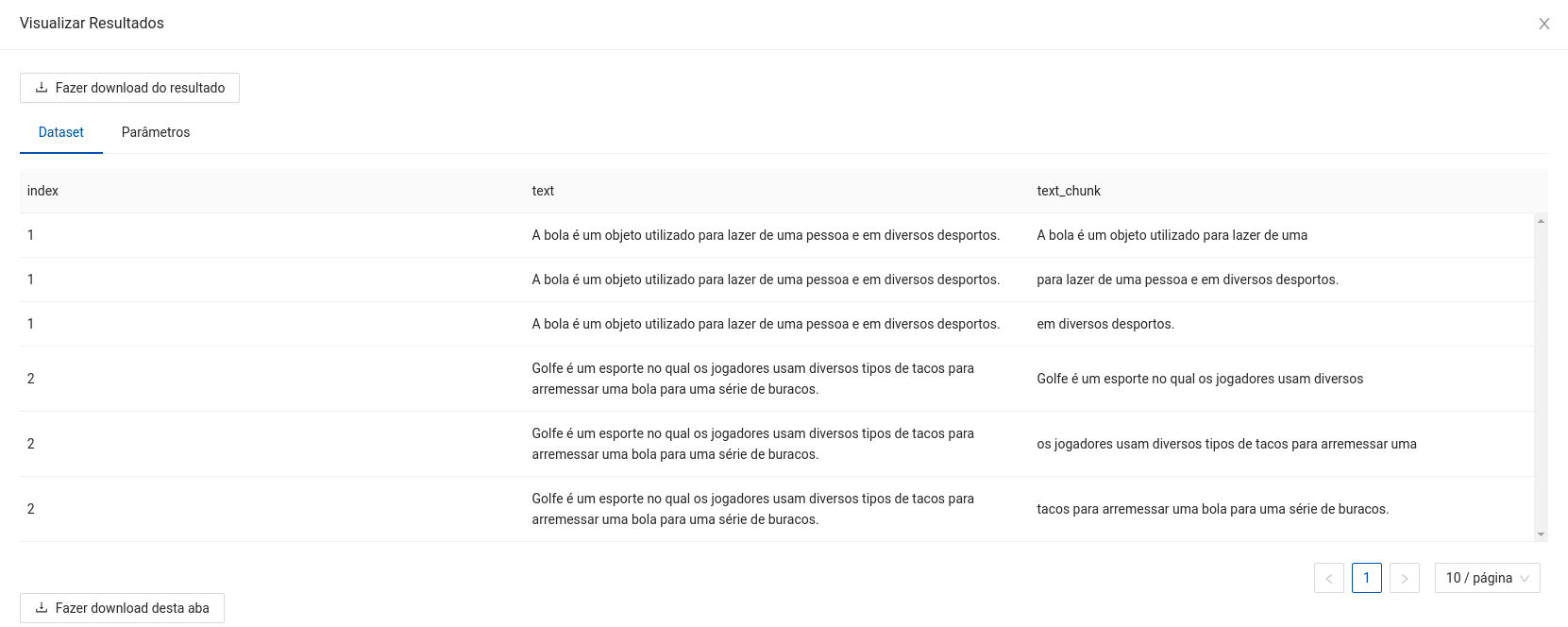
- Dataframe com o texto de entrada e os chunks produzidos (Replicando os dados).
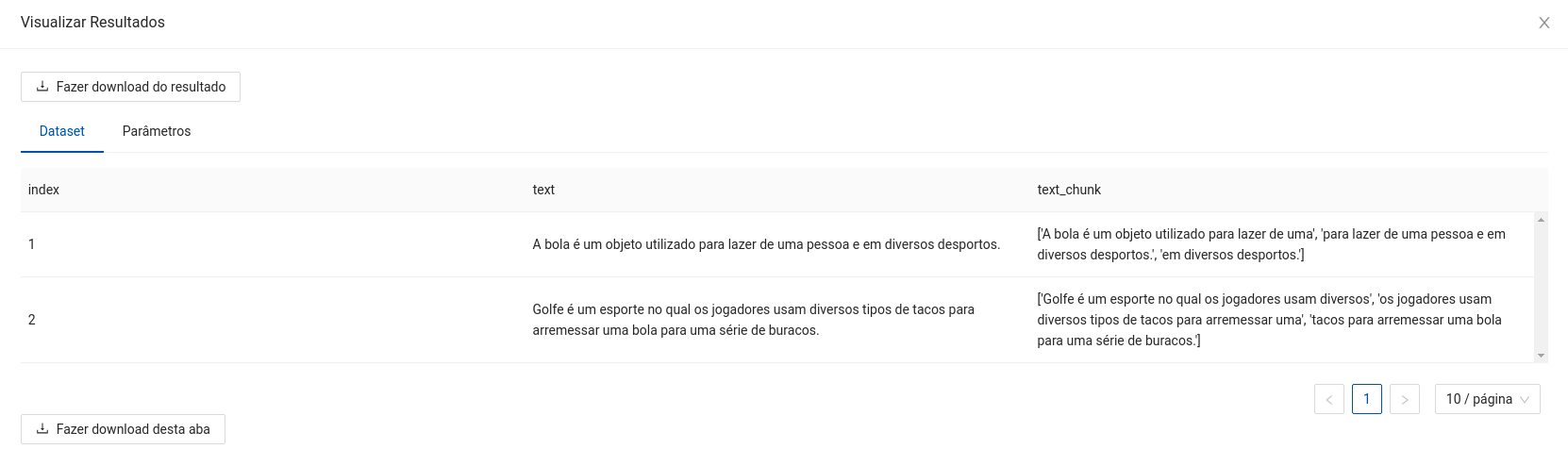
- Dataframe com o texto de entrada e os chunks produzidos (Sem replicar os dados).
Na implantação, espera-se uma requisição do tipo POST com os dados em formato JSON, com os campos ndarray e names seguindo a mesma estrutura dos dados utilizados na experimentação, em que ndarray refere-se aos valores, e names aos nomes das colunas de entrada. Um exemplo de uso seria:
$ curl --header "Content-Type: application/json" https://URL-DO-MODELO-IMPLANTADO -d "{"data":{"ndarray":[[1, "A bola é um objeto utilizado para lazer e em diversos desportos."]], "names": ["index", "text"]}}"
Espera-se como retorno um objeto JSON contendo os campos ndarray e names, referentes ao array de valores produzidos e ao nome das colunas após a aplicação. Um exemplo de saída seria:
{
"data":
{
"ndarray":[[1, "A bola é um objeto utilizado para lazer e em diversos desportos.", "A bola é um objeto utilizado para "], [1, "A bola é um objeto utilizado para lazer e em diversos desportos.", "lazer e em diversos desportos."]],
"names": ["index", "text", "text_chunks"]
}
}